Section 23 List Subsetting
23.1 Subset a list
Example list:
x <- c(1:20); y <- rep(c('R1','R2','R3'), each=4); z <- rep(c(T,F), length=4)
y <- list(Age=x, Region=y, Epi=z)
| Index | Explanation | Example. |
|---|---|---|
$ |
Get the elements of the list if the list has names | y$Age |
[i] |
Single square bracket with an integer to get the specific element of the list. The outcome is a LIST. | y[1]; y[3] |
[[i]] |
Double square bracket with an integer to get the specific element of the list. The outcome is the corresponding CLASS. | y[[1]]; y[[3]] |
| Positive integer | Select all elements corresponding to the integer value of the specific element | y[2]; y[[2]]; y[[2]][1] |
| Negative integer | Remove the element(s) corresponding to the integer value(s). Only valid with [i]. |
y[-2] |
| Zero | Select no element. Only valid with [i]. | y[0] |
| Blank | Select all elements for the specific dimension. Only valid with [i]. |
y[] |
| Logical values | Select the element corresponding to the logical value TRUE. Only valid with [i]. |
y[c(T,T,F)] |
| Names | Select the element corresponding to the named value | y$Age; y['Age']; y[['Age']] |
[i] indicates the single square bracket with an integer index value
23.2 Example
?list
x <- c(1:20)
y <- rep(c('R1','R2','R3'), each=4)
z <- rep(c(T,F), length=4)
y <- list(Age=x, Region=y, Epi=z)
y
y$Age
y[1]
y[3]
y[[1]]
y[[3]]
y[2]
y[[2]]
y[-2]
y[0]
y[]
y[c(T,T,F,F)]
y$Age
y['Age']
y[['Age']]
x <- c(1:20)
y <- rep(c('R1','R2','R3'), each=4)
z <- rep(c(T,F), length=4)
DF <- data.frame(ID=letters[1:10],
Pos=c(T,F),
Time=sample(1:100, size=10, replace=TRUE),
stringsAsFactors=FALSE)
y <- list(Age=x, Region=y, Epi=z, Samp=DF)
y
is.list(y)
names(y)
attributes(y)
str(y)
y[-1]
y[[-1]] # Error
y[4]
y[[4]]
y[-1]
y[0]
y[]
y[c(T,T,F,T)]
y['Age']
y[c('Age','Samp')]
y[['Age']]
y[[c('Age','Samp')]] # Error
y$Age
y$Age[3:5]
y$Age[-c(1:3)]
y[1]
y[1][1] # Only one element, so additional [1] redundant
y[[1]][1]
y[[1]][-c(1:3)]
x <- c(1:20)
y <- rep(c('R1','R2','R3'), each=4)
z <- rep(c(T,F), length=4)
DF <- data.frame(ID=letters[1:10],
Pos=c(T,F),
Time=sample(1:100, size=10, replace=TRUE),
stringsAsFactors=FALSE)
lstZ <- list(num=c(1:10),
char=LETTERS[1:5],
logic=c(T,F,F,T),
df=data.frame(X=c(1:10), Y=c('M','F'), Z=c(T,F,T,F,T)))
z <- list(Age=x, Region=y, Epi=z, Samp=DF, lstZ=lstZ)
z
names(z)
str(z)
z[[5]][4]
z[[5]][[4]]
z[[5]]$df
z[[5]][[4]][c('X','Y')]
z[[5]][[4]][,c(1,2)]
z[5][[1]][[4]] # Note: str(z[5])
z[5][[2]][[4]] # Error: z[5] is a list of 1Note:
Two operators to handle list:
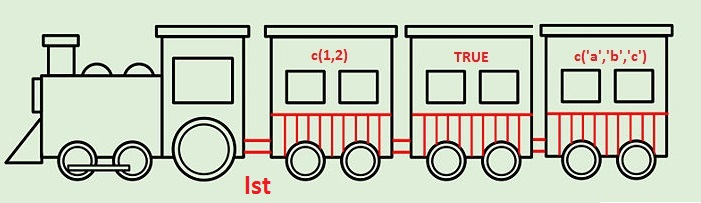
[]and[[]]If list is a train includes engine with compartments, then:
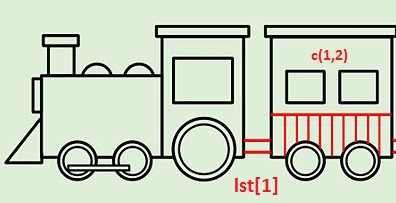
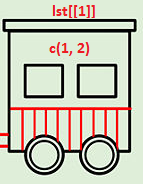
[]returns a new list (a new train): engine and selected compartment[[]]returns the contents (only the compartment)
Remember that the
[]operator always returns an object of the same class as the original. Since the original object was a list, the[]operator returns a list.Most functions cannot work on list. The function needs access to the original class.
R list can be subsetted using the combination of operators.
Partial matching of names is allowed with
[[]]and$operator.